
This is the sixth in a multi-part QOMPLX Intelligence series that examines how QOMPLX uses the real-time strategy (RTS) game StarCraft as a training ground for research to support advanced reinforcement learning and effective decision making using machine learning and artificial intelligence. We have provided links to prior installments of this series below.
Identifying and countering an opponent’s strategies is a typical and important problem in Reinforcement Learning (RL). This problem becomes even more challenging when the opponent is also intelligently adapting to our strategies. This is the so-called co-evolution problem. This blog post is a continuation of a previous blog post of ours on a similar topic, Opponent Strategy Identification.
While the focus of the previous post is on identifying what kind of strategies the opponent uses, we now shift the focus onto countering such strategies, leveraging the techniques we developed to tackle the previous challenge. In this post we still use the game StarCraft as the platform where we demonstrate our approach to this problem, since StarCraft offers both a rich and challenging RL environment where the state space is enormous, partial observability is present, and the reward (often in the form of winning or losing a game) is sparse.
Problem Description
We strive to forecast the strategies the opponent will be using in future games using information learned in the past, hoping to maximize the win rate by employing the best counter measures. The term strategy we use here is more commonly known as the build order (BO) which is formally defined as the sequence by which certain units/buildings are trained/constructed. There are numerous BOs developed by the human players for each of the three factions the game has to offer over the years. Each BO has its own strengths and weaknesses. As a result, finding a counter measure to a certain BO is a relatively easy task. However, finding the countermeasure is not enough. One must also make sure that such countermeasures are carried out in time. Timely identification of the opponent’s BO is very difficult to achieve due to the presence of the Fog of War (the main source of partial observability). This can often lead to delayed response or even the loss of the game. Hence it is vital that one executes a counter BO from the beginning of a game against the most probable strategy the opponent employs. The success hinges on the accuracy of the BO forecast. And this is the core of the problem we are trying to solve.
Methodology
We assume that the opponent is intelligently choosing the BO to maximize their win rate against us. The “UCB1” and “CP” types are two example representations of such an intelligent opponent. However, it is more appropriate to assume a black box model for how the opponent is choosing their strategies. We utilize the learned information collected from the games against the same opponent in the past and try to model how the opponent react to the previous game and which BO they are going to use in the current game most likely. The information of all the previous games we collect consists of the BOs used by the opponent and us, respectively, and the game result (either a win or a loss). We then look through all the games we have record about prior to the previous game. The number of such games is kept low (e.g., 25) to ensure prompt updates to the learned model. Next, we pick all the matching games and assign weighting to them. There are two variations when determining what a matching game is:
- A game where we use the same BO as in the previous game (denoted as “ourBO”)
- A game where the opponent uses the same BO as in the previous game (denoted as “hisBO”)
The weighting schemes are governed by three simple models, namely, uniform, polynomial, and exponential:
w1 = C1;w1 = C2xD2; w3 = exp(C3(x - D3))
where C1, C2, D2, C3, and D3 are all constants, x is the game index. Except for the constant model, the more recent a game is, the more weighting is to be assigned to it. The best weighting scheme and the associated hyper-parameters are determined via cross-validation. Below is a graph demonstrating a few examples of different weighting schemes:
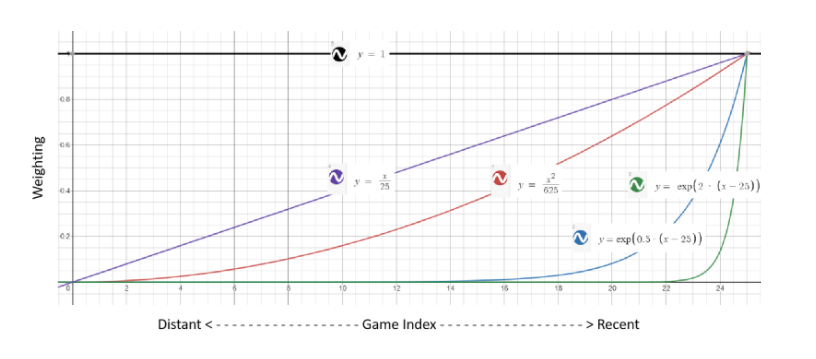
The forecast BO to be used by the opponent in the next game immediately after the previous is simply the one associated with the highest cumulative weighting.
Case Study
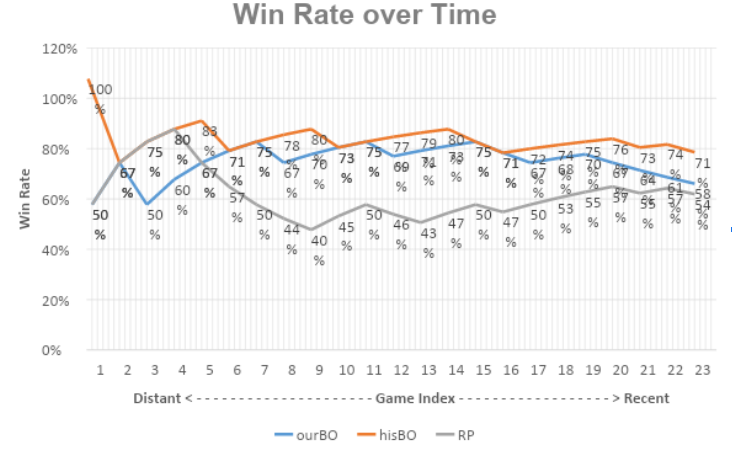
We demonstrate the effectiveness of our proposed approach for countering the opponent’s strategy here. First we select an opponent which can intelligently choose the BOs, Locutus, from the BASIL ladder. We then run 200 games against Locutus using our own StarCraft bot which is set to Randomly Pick (RP) its BOs. These 200 games are to be used to determine the type of the weighting scheme and the hyper-parameters. We then run an additional 25 games where our StarCraft bot applies the proposed approach (with both variations), as well as the RP BO choosing scheme as the baseline. To minimize the influence of map factors, all the games are run on a single map called Fighting Spirit which is well established among players. The evaluation criteria are the win rate over time and the overall win rate. Below is a graph comparing the win rate over time.
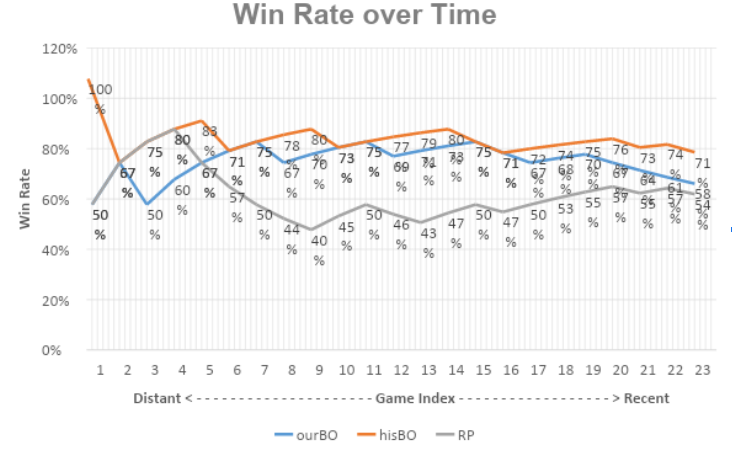
Unsurprisingly, as the baseline of this comparison, RP performed the worst. The opponent has a hard time finding the counter BO, so do we. As our BO is nearly impossible to predict, the opponent, being intelligent, is constantly seeking a counter strategy. The win rate settles around the 50% line eventually after the initial burn-in period. Variation “hisBO” performs the best, leading “myBO” by a small margin. This is potentially caused by the opponent not recognizing our BO properly, which violates the assumptions when using “myBO”. Basing opponent BO forecast on their own reaction is more reliable if our own BO identification is effective. And this is already demonstrated in our previous blog post.
| RP | ourBO | hisBO | |
| Overall win rate | 52% | 56% | 68% |
Table 1: Comparison of overall win rate
Closing Remarks
We developed a systematic approach to tackle the problem of countering the opponent’s strategy in an environment with partial observability. We utilize several weighting schemes to score the opponent’s previous strategies, and then predict the most probable BO the opponent is going to use in the next game. In the case study we demonstrated the effectiveness of our proposed approach by pitching our own StarCraft bot against an intelligent opponent.
There is still room for improvement. For example, we plan to study more opponents and further polish our model by considering the edge cases when our BO identification routine fails. We are also looking into applying the methodology to relevant domains such as cyber security to aid decision making under uncertainty and risk management.
Additional Reading
Part 1: Build Order Selection in StarCraft
Part 2: Opponent Strategy Identification Using StarCraft
Part 3: StarCraft: Pathfinding in the Fog
Part 4: Grid-Based Map & Feature Extraction
Part 5: Integrating the Grid System with Pathfinding Routines in StarCraft




Interested in learning more?
Subscribe today to stay informed and get regular updates from QOMPLX.