

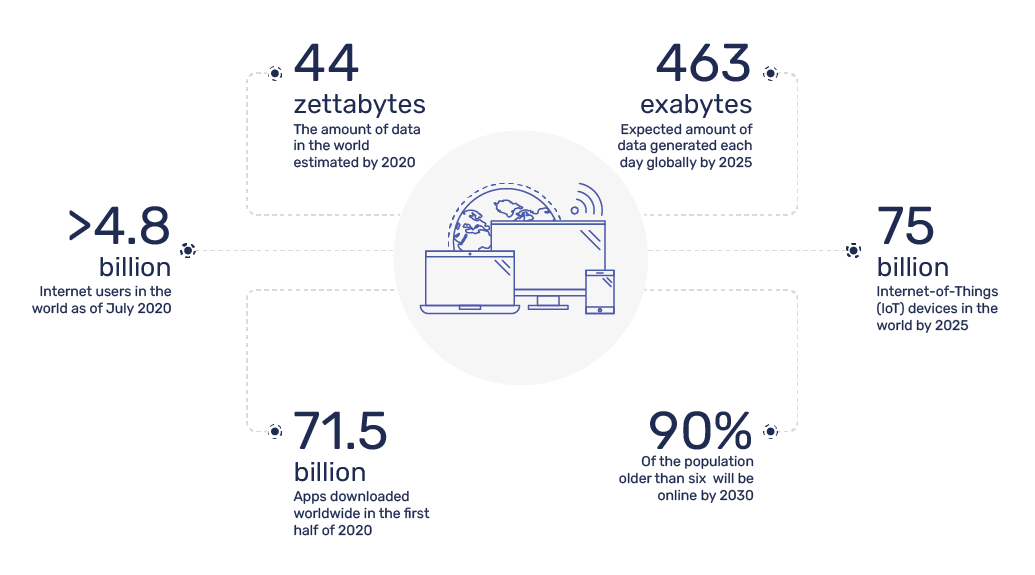
The amount of data in the world was estimated to be 44 zettabytes at the dawn of 2020. By 2025, the amount of data generated each day is expected to reach 463 exabytes globally. The growth is attributable to the continued digitization in our era, growing volume of apps and an expansion in outreach of the internet in the world, both geographically & demographically. There were 71.5 billion apps downloaded worldwide in the first half of 2020. By 2025, there would be 75 billion Internet-of-Things (IoT) devices in the world. As of July 2020, there were over 4.8 billion internet users in the world and by 2030, 90% of the population older than six will be online.
Imagine acting on that colossally gargantuan amount of data “as-is,” in its raw form, especially when sourced from a large set of diverse data sources. That is the promise of the Data Lake, a storage pattern for holding large amounts of data typically in its native form. The reality is that practitioners find that instead of clear water, operationalization is like attempting to see through murky quicksand. Promises of clear insights are overtaken by the turgid and muddled reality of so much unfiltered data.
Enterprises today have a need for acting on their data quickly. Data-driven, fast, and accurate decision-making is now critical to business success. Grappling with non-contextual, large, and often noisy data inhibits agility and momentum. The successful enterprises of tomorrow will be those that can base their decisions on high-level, contextualized representations of their data quickly, efficiently, and cost-effectively. To do this insights must be derived and context must be added. Completing numerous higher-order operations performed on raw data each time is inefficient. Imposing overly constrained or contrived schemas can result in the lowest common denominator representations of their data. Winners in this future race will also need to maintain data provenance which imparts a full data lineage as a foundational property that enables confident decision-making and proof of source and transformation processes. Data Factories preserve operational flexibility, lineage and context.
Lessons from the Past
Data Warehouse (All Hail the glorious Warehouse Schema!)
Our description of this journey is not new and there are plenty of well-documented examples from which to glean lessons. The late 1980s saw the Data Warehouse as an emerging pattern for enabling enterprise business decisions. The problem statement was similar: enterprises needed to consolidate multiple data sets from varied enterprise systems in a unified data model that offers a single lens with which to view the data and derive insights.
Then and now, many organizations developed extract, transform, load (ETL) pipelines to automate the tedious work of transforming and mapping those various datasets into proprietary warehouse data models. This was once state of the art but no longer.
Herein remain the seeds of several lasting, dire and costly problems:
- Organizations assumed, incorrectly, that a single data model could cater to all stakeholders - internal and external.
- Enterprise-wide stakeholder buy-in proved elusive, often leading to a vicious cycle of deadlocks and unfulfilled “asks” across different prospective users.
- Warehouse data models were the product of one-time business analyses and did not evolve holistically as the company grew, ultimately falling prey to the inefficiencies born of piecemeal growth.
- Slow development lifecycles delayed the availability of new data and data model changes for stakeholders.
- The cost of rationalizing and normalizing all data sources into the data model added tremendous costs to data warehouse projects - even when this wasn’t necessary for all data sets and their applications.
- Waterfall style development created disasters or disasters waiting to happen with cost and time overruns.
In 2021, enterprises that successfully implement a Data Warehouse face new challenges. Namely: their traditional Data Warehouse approach will struggle to contextualize increasingly common unstructured or semi-structured data sources. Additionally, rising volumes of data and the long turnaround times (often weeks or months) for incorporating new datasets or data attributes into the Data Warehouse make it impossible for enterprises to make time-sensitive decisions from new data.
Data Lakes (What about NoSQL and the 3Vs of Big Data?)
Data Lakes emerged out of Data Warehousing as organizations looked for ways to accomodate a higher volume of data and to overcome some of the pitfalls of data warehouses.
Data Lakes take away the notion of a single schema (star/snowflake) based data model and reduce the turnaround time for making data available to stakeholders by removing the ETL pipeline and replacing it with what is referred to as an ELT pipeline. The difference being that data transformation (“T” in ETL/ELT) is done after the loading (“L”) of data. Transformations are done on an as-needed basis, and often by virtue of queries.
By removing the need for a single data schema, Data Lakes promise improved time-to-value by addressing the delays caused by transforming data to a common model. But the Data Lake approach falls apart when organizations attempt to make decisions using the data in the Data Lake. Data Lake advocates may suggest the use of third party business intelligence or data visualization tools or proprietary SQL-based solutions with limited capabilities to deal with what quickly becomes a Data Swamp. Those suggestions quickly prove to be unrealistic in practice.
When it comes to taking that swamp of data and uplifting it via active curation into structures & persistent models that are conducive for data analytics that “end users” care about, Data Lakes abandon users mid-way. The fact is, Data Lakes just shift the burden of “transformation” to the analysis phase, making it harder to get meaningful value from data on an ongoing basis. Now the analyst or data scientist must address the complexity inherent in a plurality of data formats, sources and meanings - no actual simplification of the problem occurs.
The inherent deficiency of the Data Lake model is the presumption that data can be ingested without adherence to any larger context. Data lakes require minimal preprocessing of data at the cost of putting the onus of schematization, enrichment, normalization, and transformations on the end analyst, user, or downstream business process running queries. This presents a large burden to the ultimate data consumer given that data “as-is” is rarely usable for meaningful analysis. Transformations and transmutations may be required that change not only the data and its structures but also persistence models. And such mutations make Data Lineage a lost cause since it is rarely considered a fundamental property of the data engineering process. This is a liability disaster waiting to happen - it enables intentional or accidental misuse of data (e.g. digital redlining) without auditability or the ability to isolate harm or impact on downstream systems or outcomes. Furthermore, Data Reliability issues grow with increased concurrent use of Data Lakes, given that the growing set of tools (e.g. Hadoop, Spark, Query engines, etc.) used on top of “as-is” data in Data Lakes create read/write contentions raising multiple scenarios that can incur bad data or worse—corrupt data requiring time consuming and expensive recovery routines.
Additionally, Data Governance & Security is difficult to achieve with a Data Lake. Lack of good metadata management required for exercising governance makes it difficult to cater to the growing list of compliance & regulatory requirements such as GDPR & CCPA. And the aforementioned Data Lineage issue makes it virtually impossible to respond to data management requests (e.g. Delete My Data requests) or manage downstream derivative data sets, models, or licensing limitations.
Data Lakehouse
A more recent attempt at addressing the challenges of Data Lakes has been Data Lakehouses. Data Lakehouses are a notable attempt at tackling issues pertaining to Data Reliability, Governance and also, to some extent, Performance.
Data Lakes do not go away with Lakehouses. Data Lakehouse is an architecture that brings a layer that sits on top of the Data Lake. This additional layer is composed of technologies specifically meant to provide features such as transactions support, schema enforcements, governance, and improved metadata management for optimized performance. These features alleviate the issues pertaining to bare-bones Data Lakes, but do not address shortcomings in Data Lake solutions pertaining to the fundamental question one asks with a treasure trove of data - “how do I make decisions using this data?” The burden of data curation still remains untackled and data lineage is largely ignored.
It is important to note that, conceptually, Data Lakehouses do not move away from the Data Lake architectural pattern. The gaps and holes in Data Lakes concerning data reliability and performance are simply “plastered over'' with an additional Lakehouse layer providing an improved metadata management approach over existing primitive and archaic approaches. A few additional features such as ACID-like properties, data time-travel & savepoints are offered. But these are better viewed as enhancements over the same solution versus a new solution altogether.
It’s the same dish offered on a different plate, with prettier garnish.
Data Fabric & Data Factory
An innate and fundamental concept of the Data Lake approach is that data can stay put in a single place and need not be permanently moved in any shape or form (literally) for all subsequent downstream needs, only ephemerally transformed again and again to find specific insights. The Data Lakehouse is a further doubling down of this concept by adding an additional layer for enabling Warehouse-like access to the Data Lake. Both approaches rely on a concept rooted in data immobility that is counter to the needs of today’s fast-moving business environments. The reluctance to carry the data forward towards formalisms more conducive to downstream needs is based on avoiding the complexity involved in establishing data lineage and provenance, managing data redundancy, consistency, and mobility. At QOMPLX, we assert that such complexity needs to be managed and not avoided wholesale. Such complexity is here to stay, and both data and the value that can be derived will continue to grow. At the other end of managing this complexity is the ability to produce powerful capabilities that empower analysts, engineers, and stakeholders to act quickly and decisively with real confidence in a rapidly changing environment. Data cannot remain immobile but instead needs to be fed into pipelines and processes, dashboards and visualizations, reports, and alerts in an ever moving and endlessly continuous engine that is a Data Factory.
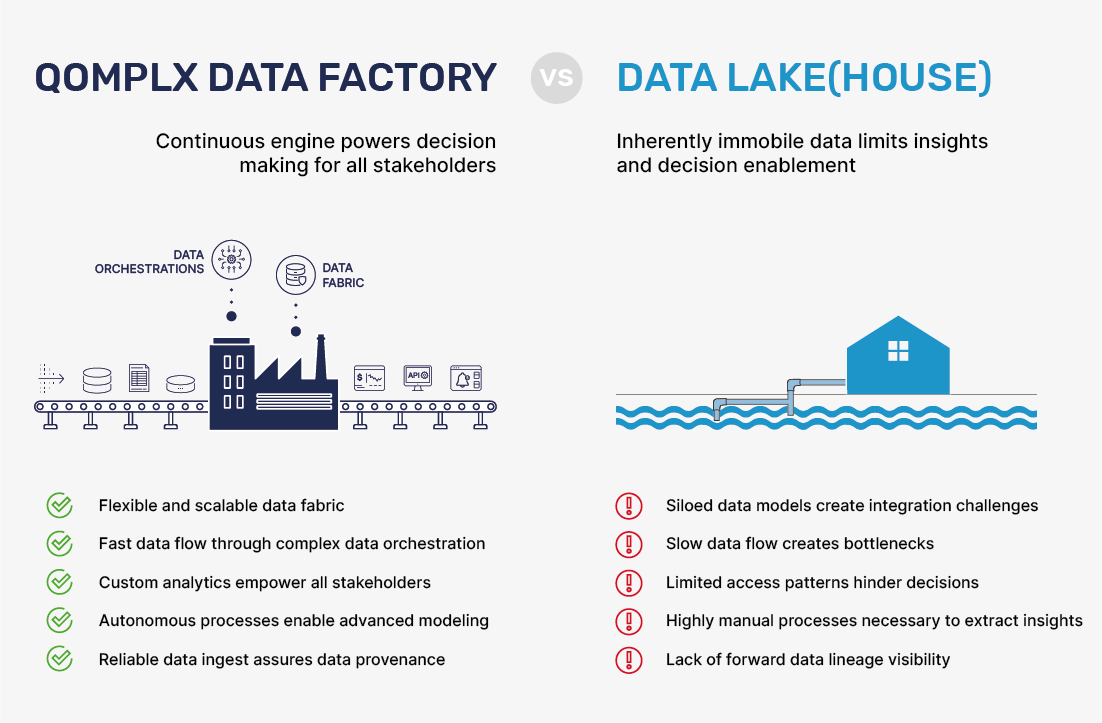
QOMPLX's formidable experience in large-scale production analytics demonstrates that disciplined data engineering and provenance management yield superior operational results, faster response to new use cases, and better cost advantages. At scale, different applications require data to be organized, transformed, and queried differently. The bigger data gets, the more specialized that data must be for effective and accurate modeling and accessibility. For example, some analytics are best performed in Time-Series structures whereas others require Wide-Column organization where query patterns are known a priori and there is a high volume of writes. Similarly, sometimes ACID-style relations are the right tool. While several key QOMPLX members personally supported massive Data Lake projects across DoD enterprises & Insurance companies, our experience and widely acknowledged external research suggests that Data Lakes fail to deliver the business/mission value return on investment 90% of the time.
Q:OS delivers the right persistence layer, by virtue of its Data Fabric, for the appropriate data model and abstracts away the operational complexity of ingesting, transforming, normalizing, and schematizing that data in order to find insight. QOMPLX’s approach of loosely coupled services with different distributed persistence layers supporting different data models promotes strong data and fault isolation, security, horizontal scaling, and a cloud-native operations paradigm for reliability and maintainability. The unification of these loosely coupled components is enabled and brought about by the QOMPLX Data Fabric. As part of the QOMPLX Data Factory, the Data Fabric provides the necessary autonomy, flexibility & power to end users to harness the potential of their enterprise’s data, yielding quicker and superior data-driven decisions.
In our next upcoming blog in this series, we cover more on QOMPLX’s Data Fabric and how it empowers our customers with an ability to achieve a varied set of access patterns catering to diverse stakeholders in a scalable and performant way.




Interested in learning more?
Subscribe today to stay informed and get regular updates from QOMPLX.